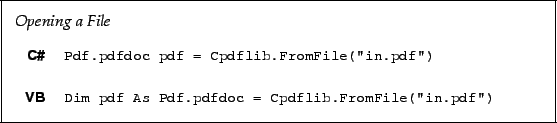
(If the file is encrypted, but only with a blank user password, it will be decrypted. This is identical to Acrobat's behaviour.)
If the file is encrypted, you must decrypt it to load it fully. This requires
either the user or owner password.

If the operations to be performed on the PDF are limited to reading some metadata, or accessing just a portion of the file, it can be more memory- and time-efficient not to load or parse all the PDF upon opening. The only caveat is that the file must be available until the PDF object is destroyed - writing to or removing that file will result in an error.
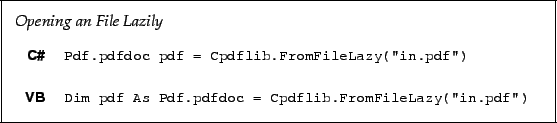
No decryption is performed here (even if the password is blank), since it would
involve loading the whole file, so you must explicitly check if the file is
encrypted using IsEncrypted and decrypt it before performing any
operation which requires the file to be in a decrypted state.